笔记:近体诗的格式(18)
――软件的失误
******************
5,个别的情况下,软件存在知识上的错误
本人的七律《寻路难》的初稿中,在试检测中见到了下面的结果:

软件认为是“平仄符合要求”。可是真的如此吗?软件通过了,是不是就可以了?我们在细致观察之后,发现在颈联中,两个“车”字居然“失对”了!
“车”字虽然是个多音字,但两个读音(che 和 ju)全是平声,在这里却被认为是一仄、一平,这就产生了联内的关键字的平仄失对的情况,可见软件把车字当成了仄声字,是错的。
这个问题很有迷惑性,如不仔细研究,就上当了!
还有,检测软件的数据库中存储的数据本身有错误,例如在《词林正韵》中,“苹”是第十一部的字,不是第六部的字。可在具体检测词的时候,它却判定苹字是第六韵部的字,而不是第十一部的字。
6,不能辨别韵书中没有收入的字的平仄。
例如“菩”字,在《平水韵》和《中华新韵》中,都没有这个字。那遇到这种情况应该怎么办?我觉得这是可以依据字典的读音来确定它的平仄。考证它在古代的读音是没有意义的,既然我们不能返古复祖,写的诗歌也不是给古人看的,那还执着地追究它的古音有什么用?《平水韵》收录了8千多字,《中华新韵》中也收录了1万1千多字,居然没有“菩”字,说明这个菩字,不是常用字。那我们依据现在的读音,给它确定一下平仄,也不是毫无道理的。
在检测软件中,拉丁字、标点符号都不计文字的数量,那么在录入待检测的诗作的时候,就该避免这种情况的出现。例如“杠”和“一”不能识别(把“一”误为杠);五G的G不被记数,这时我们就要事先把它们处理成汉字,用谐音字来暂时代替它们,就可以顺利录入供检测了。
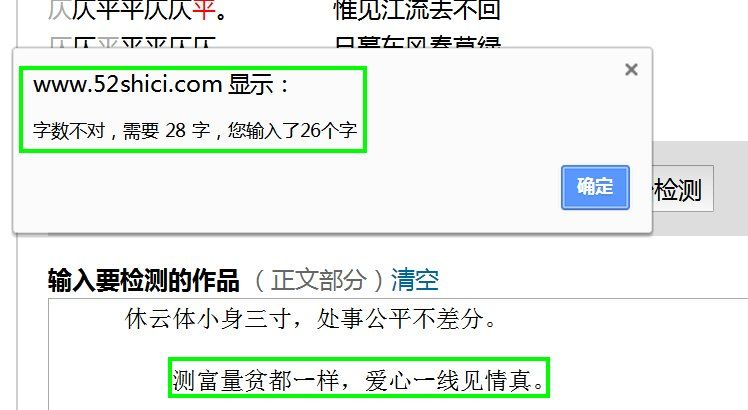
还有一种没法检测的情况,就是录入的诗词字数不对,软件拒绝检测。
这种情况,常常出现在检测几百字的慢词上,譬如录入的待检测的词,有很多很多句,其中若丢掉了一两个字,或哪怕是一个短句的时候,软件就拒绝检测,而且我们很难查出来是哪个字或哪个短句丢了,――这时候软件就用不上了,还不如直接参照词牌,一字字去核对了。当然最好还是补上缺少的字句,(或删除多了的字句),然后再来检测。
结论:
用软件检测近体诗的格式,方便快捷,但它不是很可靠的,因此不能完全依据它给出的结果,来作为判定一首诗在格式上是否合格的根据。
但它可以供我们参考,它能快速地为我们查出表面上的错误,提供多音字和重字,这就为我们指出了修改的方向。
当前,多音字的正确使用,是写近体诗中的一大难点,所以,我们在推敲多音字的读音上应该下下大功夫的。
|